Merkle Tree
A Merkle tree is a structure used in blockchain that serves to encode data more efficiently and securely. It is a collision-resistant hash function, which takes in n-inputs and outputs a Merkle root hash. Collision-resistant hash function make it impossible to generate two identical outputs to two different inputs, which in theoretical terms could be understand as a following formula:
H(x)≠H(x′)
where H(x) stands for “hash generated from input x”.
It is worth mentioning that any generated output is assigned to a concrete input. For example, H(x) will always be y, while H(x’) will always be y’. We are getting a little ahead of ourselves, but consider the following:
function takes in input x,
it checks whether output H(x) already exists,
If it exists, it returns that output,
If not, it creates a new output, associates it to this input, and returns that out.
Merkle trees are also known as “binary hash trees”.
What is it used for?
Hash trees are useful for verifying data stored, handled, and transferred in and between computers. They are very helpful in ensuring that received data (e.g. from other peers in a peer-to-peer network) are undamaged and unaltered.
The biggest advantage of Merkle tree usage is that a prover (who has a large set of data) can convince a verifier (who has access to the set’s Merkle root hash), that a piece of data (e.g. a single transaction) is in that set just by giving the verifier the Merkle proof. This kind of action is secure and trustworthy, not to mention easy to verify since a verifier doesn’t have to download the whole blockchain to confirm a single transaction or single piece of data.
A Merkle proof is a small part of a Merkle tree.
To sum up, Merkle proofs make it possible to verify that a particular piece of data is a part of a hash tree and/or wasn’t in any way altered.
How does it work?
Let’s start by explaining the graphic below:
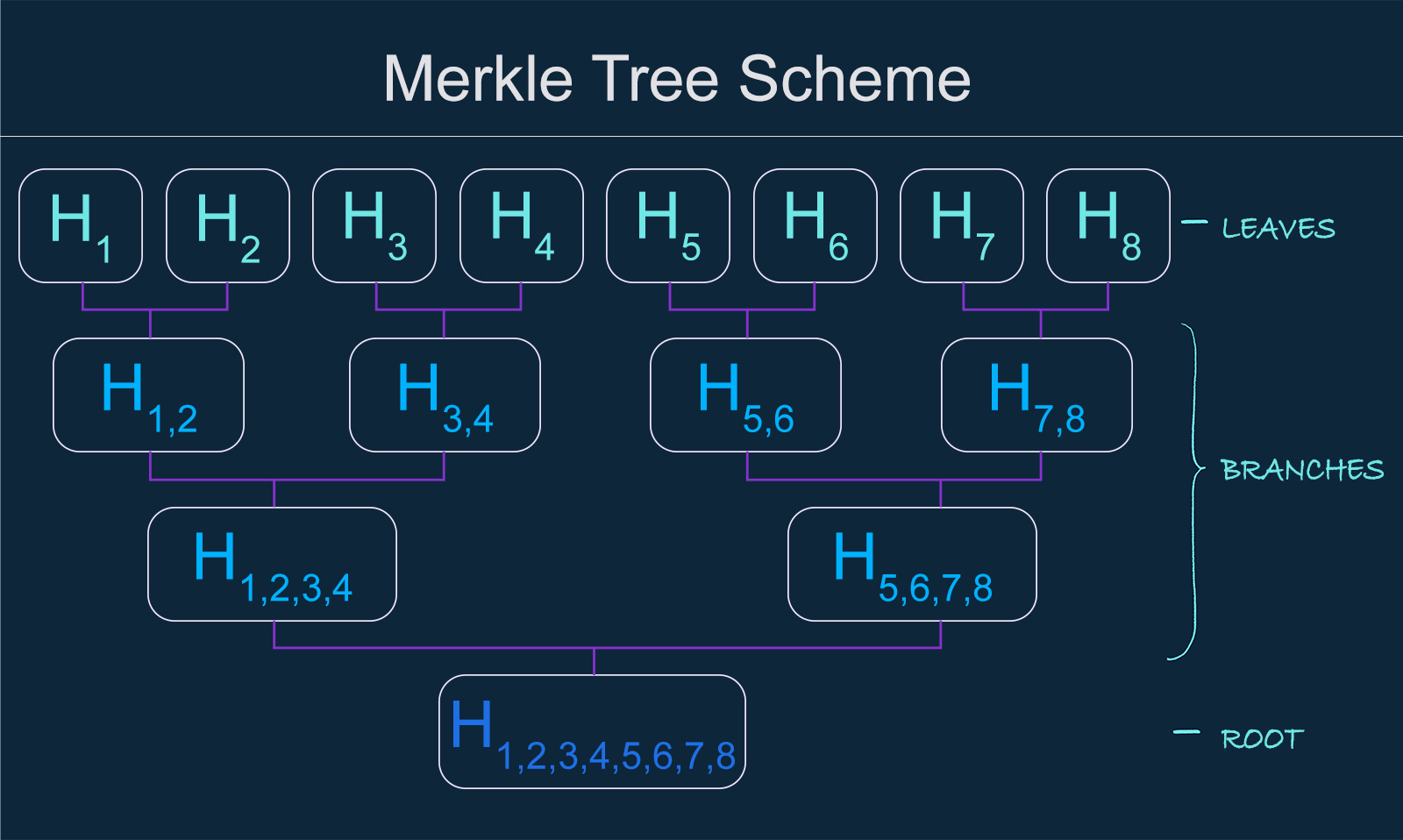
This Merkle tree scheme depicts the main work scheme within a Merkle tree. As you can see, there are three main parts: leaves, branches, and root.
Leaves are hashes of blocks of data. That’s the first level of hashing. Next, every two hashes are concatenated and hashed again into one hash till there are only two of them left. This level of hashing is called branches, and it involves every level where concatenation takes part. The last level is the root where the last two hashes are concatenated one last time and hashed, which creates the Merkle root hash in the end .
If the number of blocks on any level of a Merkle tree are odd, then the left out hash is duplicated and hashed with itself.
A Merkle tree takes an arbitrarily-sized input and then outputs fixed-size hashes. It works similar to “compressing”, which is desirable since verification should be fast, secure, and efficient, and this can be reached thanks to a small size of data.
To simplify this, we can say that a Merkle root hash is a concatenated hash value of all block hashes:
Note
Notice that instead of keeping n hashes, you could just keep one root hash created from all the previous ones. This is very efficient and saves some space – that’s why we can compare it to a compression.